编者按:日前,清华大学电子工程系教授、系主任,启明创投投资企业无问芯穹发起人汪玉教授在首届魔搭开发者大会发表主旨演讲。他分析了当下端侧大模型发展面临的核心矛盾,并提出了涉及模型层面、软件层面及硬件层面的软硬协同破局路径。围绕行业发展趋势,他指出,边缘设备将不再仅仅依赖云端进行推理,能够独立完成更为复杂的任务,从而为具身智能、自动驾驶等场景提供更高效的解决方案。汪玉教授也分享了未来智能的方向以及构建下一代智能数据基础设施需要聚焦的两大路径。
启明创投微信公众号经授权转载。

清华大学电子工程系教授、系主任,无问芯穹发起人汪玉教授
日前,首届魔搭开发者大会在北京开幕,本次大会以“模力引领跃迁,开源驱动创新”为核心主题,汇聚了来自全球顶尖高校、科研机构及科技企业的千余名代表。清华大学电子工程系教授、系主任,启明创投投资企业无问芯穹发起人汪玉教授受邀出席大会,并发表《边端智能的下一站:硬件创新与端侧AI的技术突破与挑战》主旨演讲。演讲以软硬协同为核心方法论,具身智能为未来锚点,聚焦大模型在端侧部署的挑战与解决方案,系统性地呈现了端侧AI从挑战到技术突破的全景。

汪玉教授从AI 2.0时代端侧智能的快速发展切入,指出当下端侧大模型发展面临着核心矛盾:云端大模型尺寸的持续扩大与终端有限算力形成巨大鸿沟。与此同时,传统芯片工艺面临物理极限,硬件发展的速度远远跟不上模型变大的程度,亟需系统性破局方案。
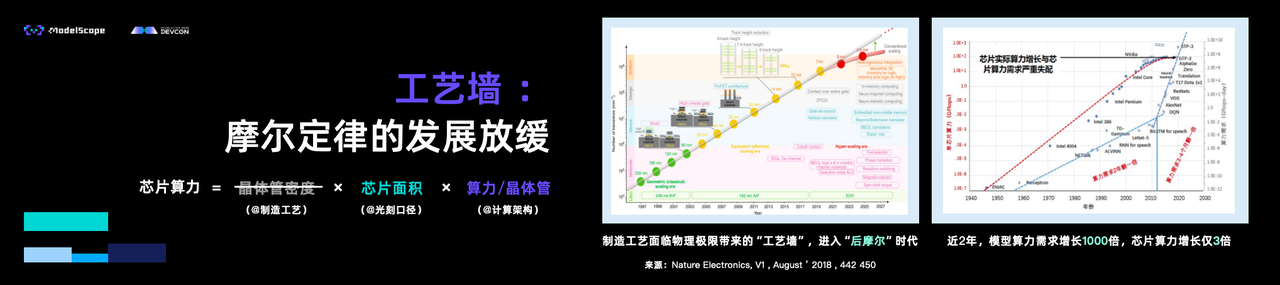
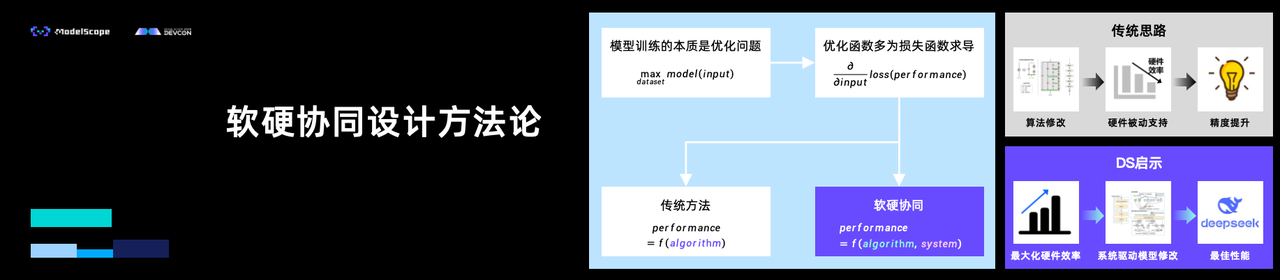
据此,汪玉教授提出软硬协同破局路径。在模型层面,通过整合算力、数据及开发者社区资源,构建高效小模型。如无问芯穹与魔搭社区联合推出的端侧全模态大模型Megrez-3B-Omni,在研发过程深度融合软硬件协同优化,实现了推理速度与精度的优异平衡,且在图文音多模态任务中均实现当时行业的最佳推理性能。在软件层面,需要开发面向通用场景的推理优化软件。以无问芯穹Mizar智能终端加速推理引擎为例,该引擎是面向PC、算力盒子等智能终端打造的自主可控大模型软硬件适配平台,实现了多种应用场景下推理速度的大幅提升以及功耗和内存占用的显著降低,将AI能力真正转化为终端设备的内生基因。在硬件层面,则需依托定制化加速器及新器件/新计算范式,突破传统架构限制以显著提升能效与处理速度。如无问芯穹自研的大模型专用推理处理器LPU IP,支持文生文、文生图、文生视频等多模态大模型,可支持3D堆叠DRAM,在低端工艺/低算力FPGA上,实现算力和能效超越高端工艺/高算力GPU。通过“算法-软件-架构-工艺”协同优化,大幅领先国内外主流芯片,实现端侧大模型性能和能效大幅提升。
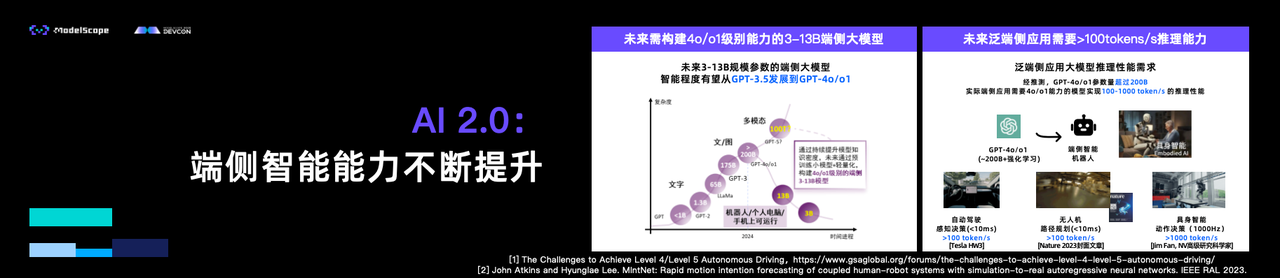
汪玉教授表示,AI 2.0时代,模型的知识密度将不断提升,通过预训练小模型和轻量化技术,构建出4o/o1能力的端侧小模型,模型尺寸可缩减至3-13B,适应端侧设备的硬件资源限制。对于泛端侧应用场景的大模型推理,未来的推理需求将超过100tokens/s,以满足实时应用的需求。这一发展趋势预示着边缘设备将不再仅仅依赖云端进行推理,能够独立完成更为复杂的任务,从而为具身智能、自动驾驶等场景提供更高效的解决方案。
展望未来,汪玉教授认为未来智能的方向可能是具身智能和群体智能。具身智能通过在实际系统中部署运行并实现环境交互,将决策能力转化为现实生产力;群体智能则通过协同拓展感知、决策与执行空间,全面提升系统能力。因此,构建下一代智能数据基础设施需聚焦两大路径:一是优化算力基础设施,让大家都有算力可用,支撑研究和工业的发展;二是建立数据基础设施及配套硬件,支撑未来的具身智能发展。“边端智能的未来需要学术界与产业界的双向奔赴,”汪玉教授强调,“只有当硬件创新与算法突破形成闭环,才能真正释放AI改变物理世界的潜力。”
